宽带慢速VCSEL共封装光学元件:
面向AI规模扩展的后铜架构
2026年3月16日 作者: 高意
来源:Jean Teissier;Manuel Kohli。《基于VCSEL的CPO在人工智能数据中心中的规模化应用——现状与展望》。白皮书,年份:2026
人工智能数据中心的后铜时代
人工智能训练基础设施正在重新定义数据中心内部连接的要求。在现代 AI 集群中,纵向扩展网络(即连接短距离内 GPU 的高带宽网络架构,范围从机架到 Pod 级别)在模型训练期间承载了大部分流量。随着模型规模和计算密度的持续增长,互连性能已成为系统的主要瓶颈。
几十年来,铜缆一直是短距离通信的基础。然而,当每通道速率超过 200Gbps 时,铜缆在提升速度方面面临着根本性的物理和架构限制,包括:
- 由高速串行器/解串器(SerDes)数字信号处理器 数字信号处理器)驱动的能耗上升
- 数据速率提高时,覆盖范围缩小
- 均衡和重定时带来的额外延迟
- 物理拥塞限制了带宽密度
将信号从处理器传输到电路板边缘,在传输尚未开始之前,每比特就已经消耗了几皮焦耳的功耗,并产生了数百纳秒的延迟。若要通过铜缆进一步扩展带宽,则需要更高的串行器/解串器(SerDes)速率和更强大的数字信号处理能力——这不仅会增加功耗和复杂度,还会影响传输距离。
为了实现网络规模扩展,AI 基础设施不得不迈入“后铜缆时代”。这一范式转变要求尽可能缩短铜缆走线长度,从而降低功耗。未来的解决方案是将光学收发器 处理单元,最终实现二者的共封装。
共封装光学元件:一场结构性变革
共光学元件 CPO)将光学引擎直接集成在处理器旁边,从而减少了电信号的传播损耗。通过优化整个链路,CPO 方案能够通过减少甚至消除电数字信号处理器,大幅降低整体能耗和延迟。但这也会对光学引擎施加更多限制,既提高了高温环境下的可靠性要求,又缩小了允许的占用空间。
然而,摒弃铜缆的主要优势在于光域内的空间复用或波长复用。因此,CPO 能够优化整个链路的关键指标:降低能耗,同时实现更高速、更稳定、更可靠的链路。
当前设计中面临的问题已不再仅仅是选择铜还是光学元件?
它是:
“快而窄”——还是“宽而慢”?
“快速窄通道”与“宽通道慢速”架构
当前的光学实现方案是对传统铜缆模式的延伸:通过采用PAM4调制和先进的数字信号处理器,以更少的数据通道实现高速传输。这种“高速窄通道”的方法既保持了与现有高速SerDes架构的兼容性,又能够通过更少的数据通道来满足所需的总带宽。但这种方法的代价是:对信噪比的要求更高、需要增加处理阶段,以及能耗开销的增加。
该替代模型更侧重于并行性,而非每通道的高速度。在 宽而慢(WaS)架构中 :
- 更多光纤通道以中等比特率运行
- 可以使用NRZ调制
- 数字信号处理器 有所降低或完全取消
较低的每通道速率可缓解信号完整性约束,从而实现电子电路的简化、鲁棒性的提升以及每比特能耗的降低。对于人工智能扩展网络——其中总带宽、效率和可靠性至关重要——宽带低速架构与系统级优化天然契合。它不再强制采用时分复用,而是将其替换为其他类型的复用,例如空间复用或频谱复用。
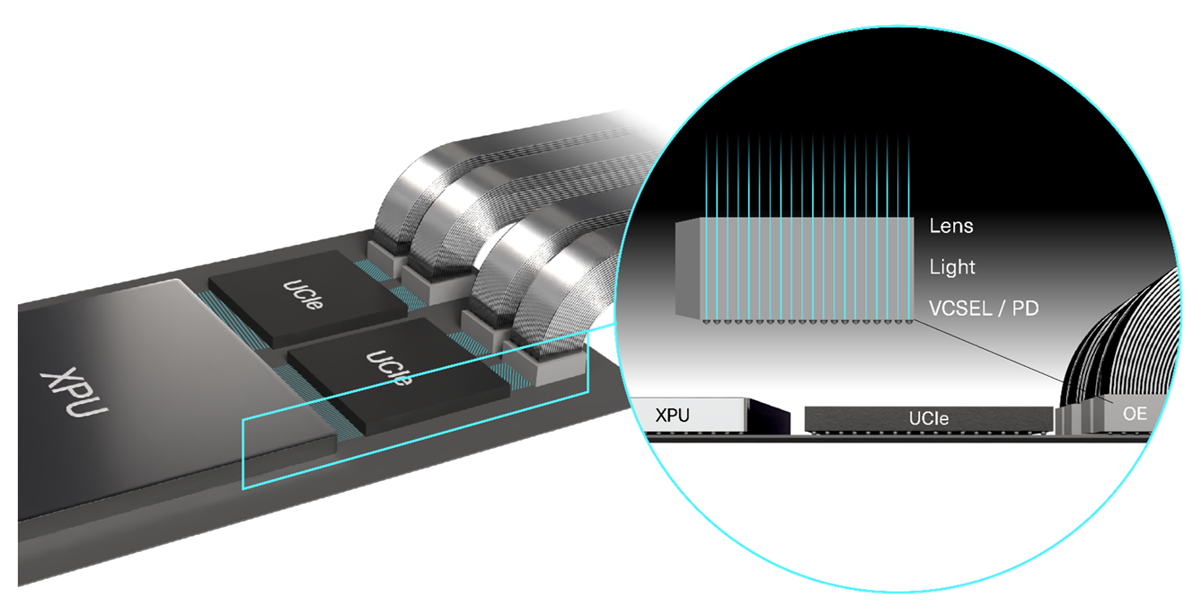
VCSEL CPO:适用于各种速度的节能互连方案
垂直腔面发射激光器 VCSEL)兼具高效率、可扩展性和成熟的制造工艺。这使得它们成为CPO应用的理想选择,无论每通道速度如何。
各种码率下均表现出色
VCSEL 适用于各种工作速率,并在宽广的工作范围内保持出色的墙插效率。这种多功能性加上其小巧的体积,在不牺牲能效的前提下,提供了设计上的灵活性。
久经考验的制造工艺与可靠性
VCSEL技术已在数据通信 应用数十年,拥有丰富的制造经验和可靠的现场可靠性。在中等速度下运行可进一步降低电气和热应力,从而确保长期稳定性。
直接调制与信道独立性
VCSEL 可以以阵列形式部署,其中每个发射器均可独立于其他发射器进行驱动。每个 VCSEL 通道均采用直接调制,且在物理上是相互独立的。这使得:
- 行级隔离
- 局部故障隔离
- 备用车道的实际实施
- 在集群层面增强韧性
与依赖共享光路的架构不同,物理上独立的信道有助于防止故障在系统中蔓延。
“广泛而缓慢”方法的优势
大规模人工智能系统中的延迟
尽管能效备受关注,但在高度同步的 AI 训练系统中,延迟同样至关重要。采用复杂数字信号处理器 的高速 PAM4 链路数字信号处理器 额外的处理阶段和重定时开销。宽带低速 NRZ 架构则能降低信号处理复杂度并简化电路链路,从而有助于最大限度地减少延迟并降低成本
可靠性和链路稳定性
模型的训练阶段对任何中断都非常敏感。扩展链路发生一次中断,就可能需要从上一次备份点重新启动该阶段,从而对成本产生重大影响。
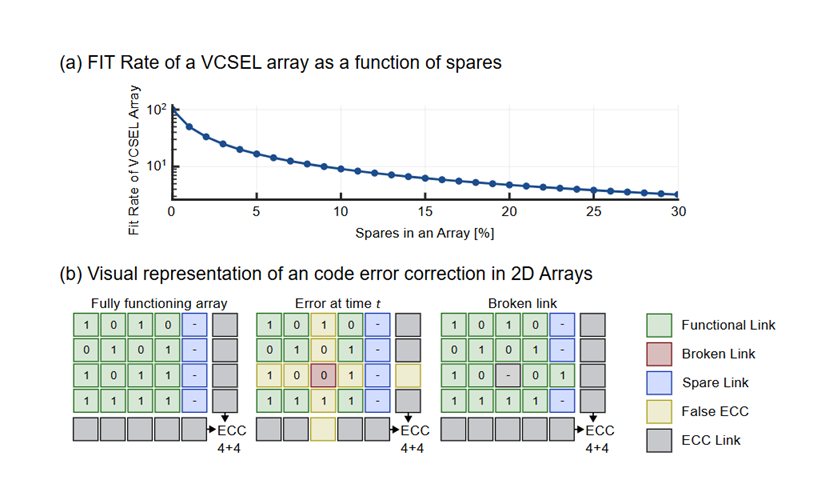
宽带宽、VCSEL 阵列 通过以下方式VCSEL 阵列 可靠性:
- 每条车道的车流量减少,从而减轻了交通压力
- 信号处理简化,决策点减少
- 独立光通道
- 实用的备用通道冗余
由于每个通道独立运行,故障仅局限于局部,而不会在共享的光学结构中传播。采用“宽带慢速”策略,可在极小的开销下引入冗余。此外,还可引入简单的错误校正码(ECC),且不会造成明显的延迟或能耗开销。
带宽密度:一项关键的扩展指标
除了能效之外,AI互连的扩展日益依赖于带宽密度,通常以每平方毫米太比特每秒(Tbit/s/mm²)为单位表示。
VCSEL 阵列 在适中的每通道速率和细密间距下VCSEL 阵列 ,无需依赖极其复杂的调制方案,即可实现每平方毫米数太比特的带宽密度。这为人工智能基础设施的持续发展提供了可观的增长空间。
能效:向低于1皮焦耳/比特的性能迈进
能效是衡量人工智能扩展网络的关键指标。一种平衡的“宽带慢速”VCSEL CPO架构——融合了简化的电子电路、精简的数字信号处理器、高效的驱动器以及精心设计的电光协同方案——有望实现端到端总链路能耗低于1皮焦耳/比特。
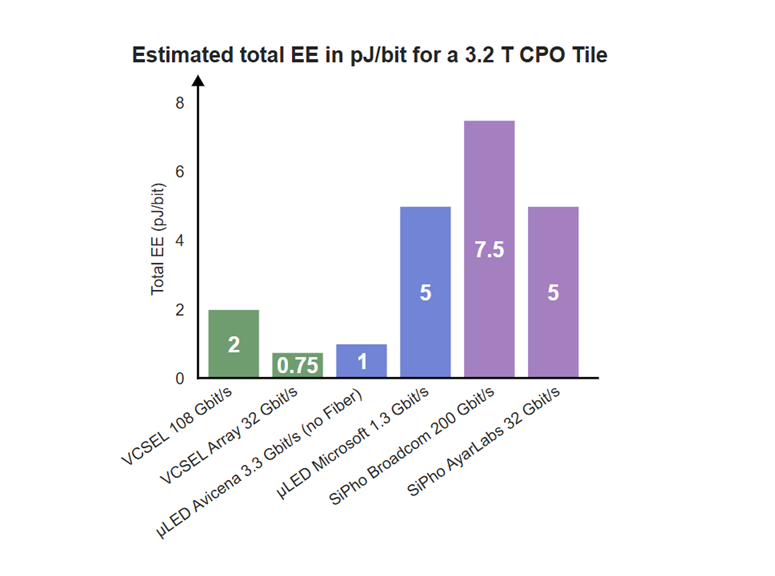
在新兴光学方法中的定位
目前,业界正在探索多种适用于人工智能数据光学元件 共封装光学元件 的技术,包括微发光二极管(microLED)发射器和硅光子学 解决方案。
每种方法都有其独特的优势。基于VCSEL的宽带慢速CPO技术实现了以下要素的均衡结合:
- 高墙插头效率
- 直接调制发射极
- 在广泛的速度范围内均能保持高能效
- 光纤兼容性
- 信道级独立性
- 成熟的制造能力
这种平衡使得宽带慢速VCSEL架构成为人工智能扩展网络中一种极具吸引力且可扩展的选项。
结论:迈向以光子学为先的人工智能基础设施
光学元件 人工智能扩展网络光学元件 从铜缆向光学元件 过渡已全面展开。下一阶段的架构演进可能是从“高速窄带”设计转向“宽带低速”设计,即针对效率、延迟和弹性进行优化的高度并行光纤网络。
采用宽带宽、低速VCSEL光学元件 共封装光学元件 迈向“光子优先”AI基础设施的切实可行路径——它能够满足新一代AI数据中心对性能、能效和可靠性的要求。该技术依托成熟的生态系统,具备经过验证的成本模型和大规模可靠性。这并非渐进式改进,而是由并行化和简化驱动的架构变革。 随着铜缆逐渐接近其根本性能极限,光学元件 再被视为铜缆互连的直接延伸;相反,系统架构应充分利用光域中的复用技术进行全面优化。



